问题导读
1.如何将namenode与SecondaryNameNode分开?
2.SecondaryNameNode单独配置,需要修改那些配置文件?
3.masters文件的作用是什么?
![]()
我们这里假设你已经安装配置了hadoop2.2,至于如何配置可以参考,hadoop2.2完全分布式最新高可靠安装文档。
在这个基础上,我们对配置文件做一些修改:
1.增加masters文件
- sudo vi masters
复制代码
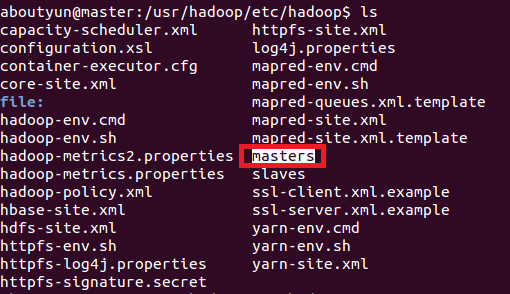
这里面放什么内容还是比较关键的,这里我们指定slave1节点上运行SecondaryNameNode。
注意:如果你想单独配置一台机器,那么在这个文件里面,填写这个节点的ip地址或则是hostname,如果是多台,则在masters里面写上多个,一行一个,我们这里指定一个
- slave1
复制代码

2.修改hdfs-site.xml
在下面文件中增加如下内容:(记得下面亦可写成ip地址,这里为了理解方便,写的是hostname)
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
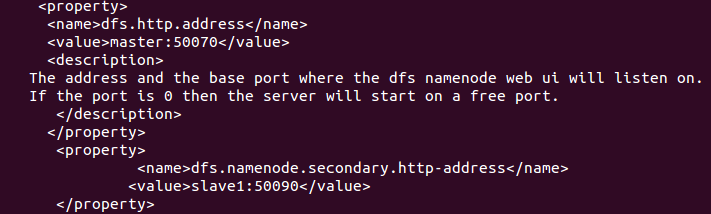
3.修改core-site.xml文件
- <property>
- <name>fs.checkpoint.period</name>
- <value>3600</value>
- <description>The number of seconds between two periodic checkpoints.
- </description>
- </property>
- <property>
- <name>fs.checkpoint.size</name>
- <value>67108864</value>
- </property>
复制代码

上面修改完毕,相应的节点也做同样的修改
![]()
下面我们开始启动节点:
- start-dfs.sh
复制代码
输出如下内容:
- Starting namenodes on [master]
- master: starting namenode, logging to /usr/hadoop/logs/hadoop-aboutyun-namenode-master.out
- slave2: starting datanode, logging to /usr/hadoop/logs/hadoop-aboutyun-datanode-slave2.out
- slave1: starting datanode, logging to /usr/hadoop/logs/hadoop-aboutyun-datanode-slave1.out
- Starting secondary namenodes [slave1]
- slave1: starting secondarynamenode, logging to /usr/hadoop/logs/hadoop-aboutyun-secondarynamenode-slave1.out
复制代码

然后查看节点:
(1)master节点:
- aboutyun@master:/usr/hadoop/etc/hadoop$ jps
- 5994 NameNode
- 6201 Jps
复制代码

(2)slave1节点
- aboutyun@slave1:/usr/hadoop/etc/hadoop$ jps
- 5199 SecondaryNameNode
- 5015 DataNode
- 5291 Jps
复制代码

(3)slave2节点
- aboutyun@slave2:/usr/hadoop/etc/hadoop$ jps
- 3628 DataNode
- 3696 Jps
复制代码

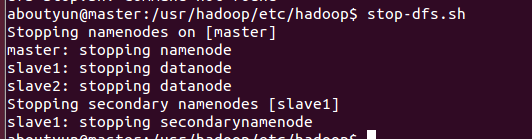
停止节点:
- master: stopping namenode
- slave1: stopping datanode
- slave2: stopping datanode
- Stopping secondary namenodes [slave1]
- slave1: stopping secondarynamenode
复制代码
补充
Secondarynamenode的单独启动和停止
启动:
bin/hadoop-daemons.sh –config conf/ –hosts masters start secondarynamenode
停止:
bin/hadoop-daemons.sh –config conf/ –hosts masters stop secondarynamenode